
Sauvez le web, faites des copies !


Et non, ceci ne s'appelle pas faites des backups (qui est un article que j'ai fini par jeter car je ne lui trouvais pas grand intérêt), mais bien copier le web.
Pour vous qui me lisez (vous qui découvrez mon blog au travers de cet article), vous n'êtes pas sans savoir que je suis plutôt orienté technique et surtout technologie décentralisée voir "à l'ancienne" (coucou IRC). Et dans ces technologies à l'ancienne je vois le web, remplis de blog, de créations tout aussi sympathiques que ephémères. Car oui, un blog, un strip ou autre peuvent disparaitre à tout moment et cela pour de nombreuses raisons :
- L'auteur ne peux plus s'occuper de son blog et l'abandonne / le supprime
- L'auteur a voulu supprimer son blog volontairement pour diverse raison
- L'hébergeur a fermé, l'auteur n'a pas voulu remonter son blog ailleurs
- L'auteur a fermé son blog à cause d'un évènement extérieur (réception d'insulte, de menace par exemple).
- L'auteur est décédé, son nom de domaine disparait donc.
Mais ce web, il évolue constament et intrinsèquement perds des perles, des articles ou des oeuvres introuvables par la suite. Parfois on retrouve ce qu'on cherche dans archive.org. Parfois on pleure. Récement j'ai eu ce soucis avec deux articles de blog que j'avais mis au chaud car ils contenaient tout deux des ressources / des aides mémoires que j'utilisais de temps en temps. Et bien ces deux blogs ont disparus. Ils sont encore disponibles dans archive.org mais le site est long à répondre... Et il peut disparaitre également ! (Même si ce n'est pas prévu).
Mais dans ce cas, on a qu'à tout mettre sur Medium, Google ou Facebook non ?

Non, pas du tout. Car même si, tout comme archive.org, ces sites ne sont pas censé disparaitre, ils peuvent cependant très bien bloquer votre contenu (pour diverses raisons tout aussi improbables les unes que les autres), le supprimer, le perdre (oui oui), le rendre rendre accessible par abonnement ou même vous demander de payer pour que vous puissiez le laisser public. Au final déposer votre contenu sur ce genre de site vous rend dépendant et vous laisse à leur merci.
Si quelqu'un fait son blog, ses articles peuvent disparaitre, si quelqu'un fait un article sur Medium, ses articles peuvent disparaitre. Au final est-ce pas la vie d'internet de laisser des articles disparaitrent sous une tonne de nouvelles données ?
Idée intéressante que je ne trouve pas... Réaliste.
Internet a pendant de nombreuses années été déclaré comme étant une encyclopédie accessible à tous...
Imaginez ! Nous sommes en 2020, Jules Verne rédige 20 000 lieux sous les mers et dépose ce superbe ouvrage sur son blog en accès libre nommé blog.julesvernes.nantes (ouais, j'ai hésité avec .bzh).
Mais voilà, il passe de vie à trépas en 2021. Son blog est arrêté 1 an plus tard en 2022 et l'année suivante archive.org se fait pirater et perds toutes ses données antérieur à 2023. Au final que reste t'il de 20 000 lieux sous les mers ? Rien.
Sauf qu'aujourd'hui, Jules Verne a écrit cette oeuvre sur du papier (papier qui servait aussi pour les encyclopédies). Cette oeuvre a été recopiée, imprimée, dupliquée ce qui fait qu'aujourd'hui toutes ses oeuvres sont encore présentes et accessibles.
Vous vous imaginez si toutes les oeuvres n'était que temporaires ? Plus de seigneur des anneaux par exemple.
Au final une oeuvre est immortelle car elle est recopiée.

Oui, cela peut faire peur et vous allez me traiter de pirate ! Mais sans cette copie, certaines oeuvres cinématographiques (par exemple) parut dans les années 50-60 auraient tout simplement disparues. Est-ce donc du vol où de la conservation culturel ?
Je vais même prendre un exemple : Le 5ème élement, trouvable encore en DVD, Bluray, VOD sur Youtube car il a plu. Très bien. Mais si mon lecteur DVD est trop vieux ou trop récent pour passer la sécurité des disques fraichement acheté ? Si Youtube décide de retirer Ce film de Luc Besson de son catalogue, que reste-il d'encore accessible ? Les DRM empêchent de le lire et il n'est plus accessible par un autre moyen.
Et donc aujourd'hui nous sommes capable de trouver un vieux bouquin de 150 ans mais pas un film d'il y a 70 ans ? Il est là le vice, tout est accessible facilement et nous semble fonc forcément acquis alors que nous sommes dépossédés de tout.
Avant de continuer ! Je tiens à préciser que le droit d'auteur est important et que, même si on pense que télécharger sans payer un jeu vidéo "c'est pas grave car
Tout ça est un énorme cercle vicieux.
Mais ce que je veux dire au final c'est que copier permet de garantir la survie d'une oeuvre mais que pour qu'une oeuvre existe, il faut que quelqu'un la créee et si ce quelqu'un ne peut pas manger, iel ne fera pas cette oeuvre.
Bref, ne pensez pas que j'ai dis que télécharger tout c'est bien.
Houaaaaaa mais tu nous as perdu avec ces comparaisons ignoble.
En gros un article de blog, une bande dessinée en ligne est une oeuvre comme une autre. On ne doit pas la voler mais elle peut disparaitre d'un moment à l'autre. Il faut donc la préserver.

Et c'est là où je vais vous parler d'un super outil que je viens de découvrir : archivebox.io.
Je l'ai trouvé en cherchant un moyen de faire des snapshots régulièrs de mon site car je m'en veux de ne pas avoir conservé le design original. Et puis au final l'outil semblait sympa, j'ai creusé et j'ai décidé d'importer mes liens de wallabag et shaarlii. Je découvre avec cette action que j'ai plus de 1/3 des articles que j'ai voulu lire ou partager qui n'existent plus. Et c'est dommage car les articles peuvent avoir été super bien expliqués, sont uniques, étaient très jolis ou très sympathiques à lire... Plus personne ne pourra le savoir ni le découvrir. Et ça... Ça c'est dommage car au final une partie d'internet disparait chaque jour. C'est d'autant plus dommage qu'une vidéo de chien qui pète a une durée de vie bien supérieur à un article de blog.
Bref
En 1 an 20% des liens n'existe plus. Et ça grandit de jours en jours (selon cet article)
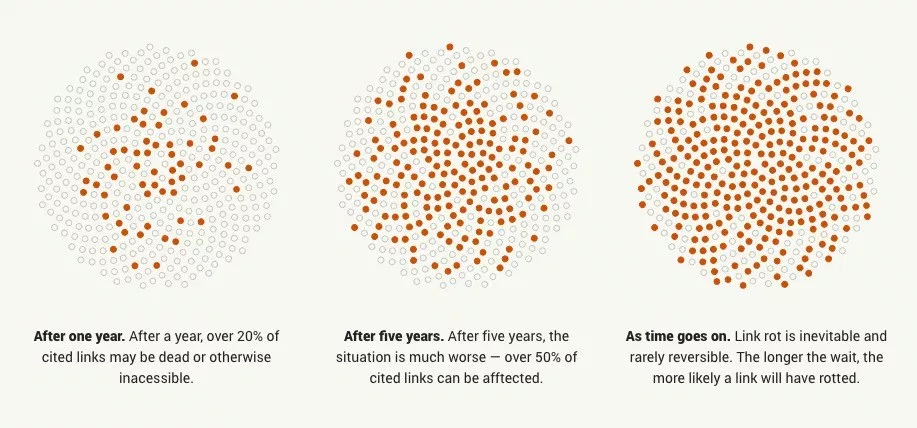
Ce qui d'ailleurs tend à se confirmer avec le fait que mon Shaarli a été ouvert courant 2017 ainsi que mon Wallabag et que j'ai 1/3 des oeuvres disparus.
Et donc, le lien avec Archivebox ?
Molo, j'y viens !
Archivebox est une sorte de archive.org auto-hébergeable écrit en python et ne nécessitant pas forcément de daemon.
Il s'installe facilement et est facilement automatisable. Un simple archivebox add https://dryusdan.space et vous avez une copie de ma page d'accueil.
Aujourd'hui l'outil continue d'évoluer. Récement il s'est doté d'une interface d'administration si jamais vous avez envie de jouer du clickodrome. Pour moi il manque trois choses :
- Le moyen de faire des snapshots d'un même site chaque mois
- Le moyen de faire un miroir complet du site
- Une doc ultra carré (celle actuelle est pas tout a fait calé sur la nouvelle version).
Mais c'est prévu !
Allez, attaquons le vif du sujet : L'outil.
Présentation
Le site possède deux interfaces. Une classique HTML sans dépendances ni serveurs qui liste chaque page sauvegardées.
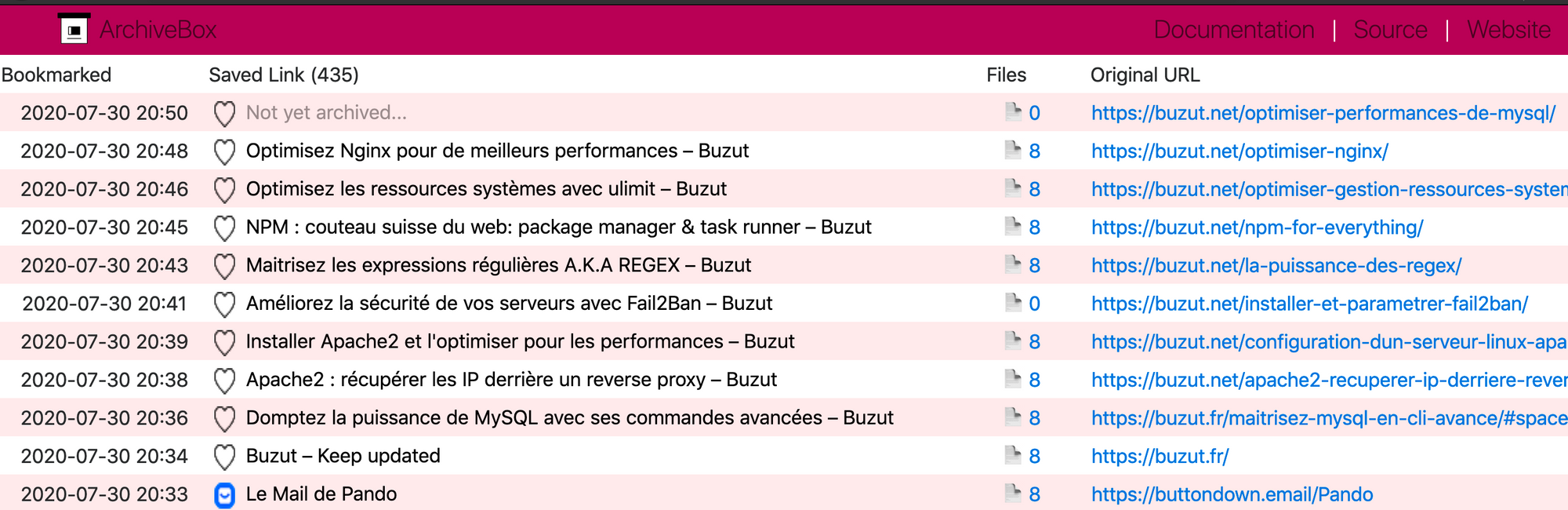
Bien sur le must dans tout ça c'est que vous pouvez cliquez sur le nom du site, à 90% du temps vous vous croyez sur le site.
Mais lorsque vous cliquez sur le petit "files" (qui n'indique pas qu'il y a 8 fichiers avec le site mais 8 captures différentes) vous trouverez une nouvelle page !
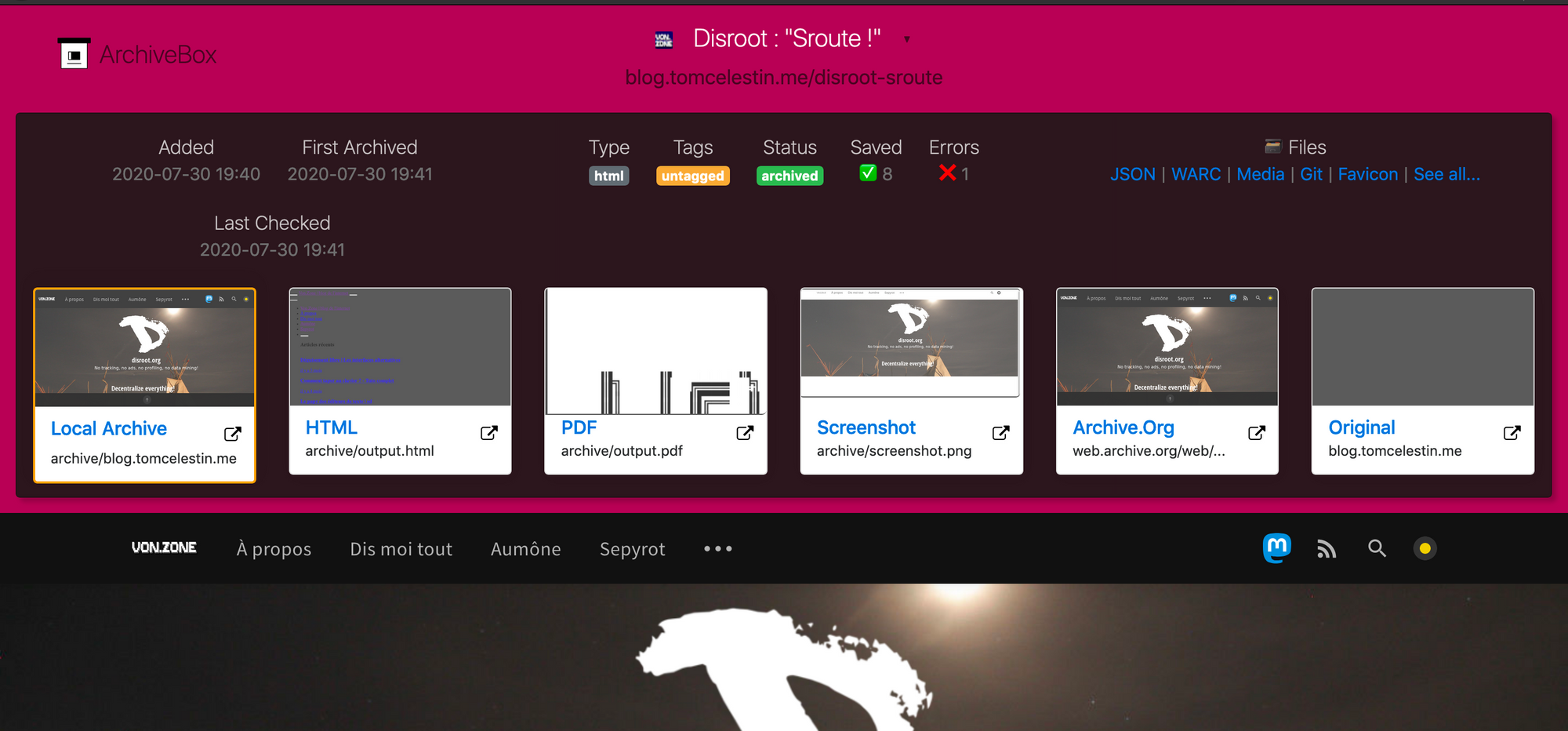
En fonction de ce que vous avez paramétré vous aurez le site en HTML, Screenshot, un lien vers archive.org... Plein de moyen pour sauvegarder ce site.
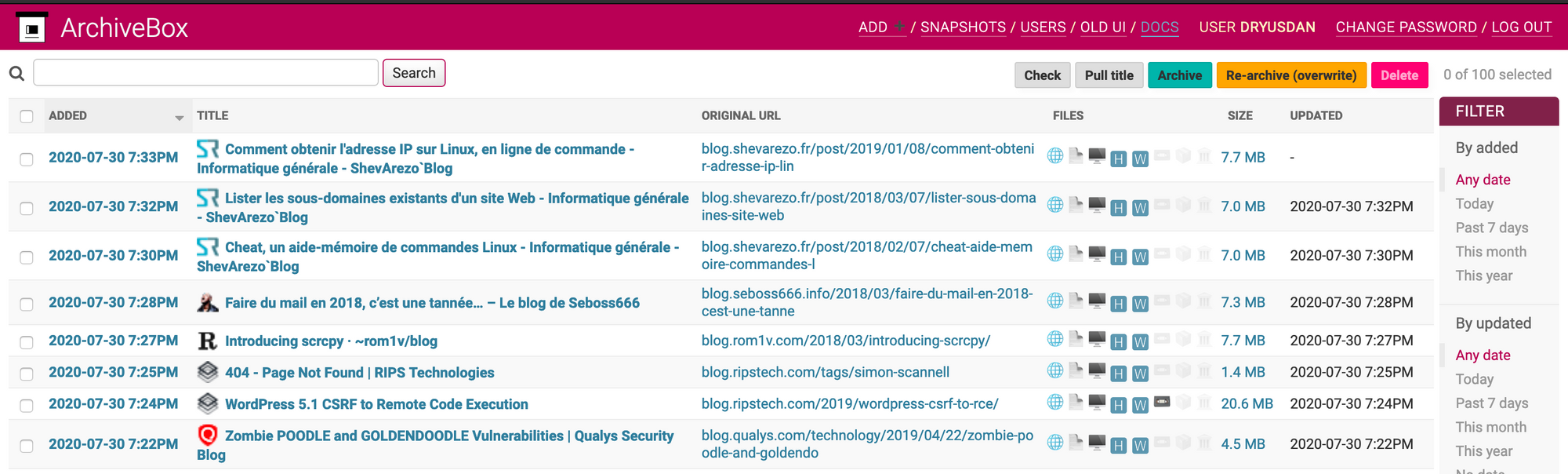
L'autre interface permet de se passer de la CLI.
Personnellement je l'utilise surtout pour la fonction recherche et supprimer.
L'installation
Il vous faut pour ce superbe tutoriel : Un Linux, Debian ou dérivé mais je sais que vous arriverez à faire la même chose sur un autre OS.
L'installation pour la version 0.4 n'est pas sur le repo git d'archivebox mais sur le site archivebox.io.
On commence par ajouter les dépendances :
apt install python3 python3-pip git curl wget youtube-dl chromiumPuis on installe archivebox
useradd -d /opt/archivebox/ -m -s /bin/bash archivebox
su - archivebox
pip install archivebox
mkdir data; cd data
archivebox init
Et là vous pouvez commencer à sauvegarder votre bout de web :
archivebox add 'https://dryusdan.space'Et le mieux dans tout ça ? L'abonnement aux flux RSS. Car Archivebox va détecter vos flux RSS et ajouter les liens qu'il croise pour les ajouter à votre collection
archivebox add 'https://dryusdan.space/feed/' --depth=1
Et lorsque archivebox a fini de copier la page, il vous indique comment consulter ça.
Bien sur j'ai mis l'admin à tourner en arrière plan et les pages HTML accessibles sur un autre domaine vu que j'ai pas mis de uwsgi, ou de gunicorn, devant l'admin n'est pas multithreadé donc pas accessible par deux personnes en simultanée. Pareillement la base de donnée utilisée est un sqlite3, donc pas de concurence.
Allez, je ne vous laisse pas mariner. Le daemon tourne grâce à systemd et l'HTML est accessible grâce à Nginx.
Pour Nginx je pars du principe que vous savez mettre en place un vhost. Je vais donc faire très bref et en HTTP.
server {
listen 80 ;
server_name archivebox.tld ;
client_max_body_size 2M;
root /var/www/archive_dryusdan_fr/www/;
index index/html;
location / {
index index.html;
autoindex on;
try_files $uri $uri/ =404;
}
}
Voilà, ça c'était pour un vhost nginx classique.
Maintenant le service avec le daemon.
Vous allez créer un petit fichier ici /etc/systemd/system/archivebox.service avec ce qui suit dedans :
[Unit]
Description=ArchiveBox
Documentation=https://github.com/pirate/ArchiveBox/
After=network-online.target
Wants=network-online.target
[Service]
Type=simple
User=archivebox
Group=archivebox
PIDFile=/var/tmp/archivebox.pid
WorkingDirectory=/opt/archivebox/data
ExecStart=/opt/archivebox/.local/bin/archivebox server 127.0.0.1:8001
Restart=on-failure
RestartSec=30
PrivateTmp=true
[Install]
WantedBy=multi-user.targetPuis rechargez systemd avec la commande systemctl daemon-reload
On a dit à archivebox d'écouter uniquement en local sur le port 8001. À vous de décidez comment vous souhaitez faire.
Le vhost arrive. Cependant faites attention, certaines fois l'application met du temps à répondre. Il va donc falloir jouer sur les timeout de nginx
server {
listen 80 ;
server_name admin.archivebox.tld ;
client_max_body_size 2M;
proxy_connect_timeout 600s;
proxy_read_timeout 600s;
proxy_send_timeout 600s;
location / {
proxy_pass http://127.0.0.1:8001;
}
}
Plus qu'une dernière petite chose, créer l'utilisateur principal. Pour ça, tapez les commandes ci dessous :
su - archivebox
cd data
archivebox manage createsuperuser
Remplissez et voilà. Maintenant vous pouvez sauvegarder le web !
Modification du 13/04/2021 : Suite à une augmentation considérable des pages que je sauvegarde, cela a ammené une augmentation de l'espace disque consommé, environs 50Go d'espace disque consommé pour 2417 pages web sauvegardé. Beaucoup de ces pages ont les mêmes fichiers. Ce sont juste des duplicats. Il y a plusieurs méthodes pour dédupliquer : avoir un système de fichier adapté tel que ZFS ou BTRFS qui va permettre une déduplication (et même une compression), ou avoir un logiciel qui déduplique (peut-être que Archivebox va proposer cette fonctionnalité là sous peu).
J'ai donc installé le superbe utilitaire rdfind et j'ai tapé la commande suivante :
rdfind -makehardlinks true -removeidentinode false -checksum sha256 /data/
Rajoutez l'option -dryrun true si vous souhaitez d'abord voir ce que ça va faire.
Si vous avez lu cette ligne et la doc vous verez qu'ici je demande a faire des liens symbolique, j'évite de supprimer quoique ce soit et j'utilise un checksum pour valider que les fichiers sont identiquent afin d'en faire un lien symbolique.
Globalement cette commande m'a permit de retirer 15Go de fichier dupliqué.

Maintenant l'instant moins drôle. Avec cet archivage, le droit à l'oublie n'existe plus car une oeuvre qui a volontairement été supprimée par l'auteur (pour des raisons légale, morale ou juste l'envie) existera toujours quelque part.
En fait c'est ça internet, des bots qui scannent et sauvegardent le web, et des humains qui vont faire une capture d'écran d'un quart d'une phrase pour la détourner ensuite et te la refoutre dans les dents dans les jours, mois voir années qui viennent. Un outil comme ça peut malheureusement servir à ce genre de fin, continuer le harcelement (aussi bien qu'un ctrl+s en fait).
En fait internet oublie ce qui est bien mais l'humain sauvegarde ce qu'il y a de mauvais. Si vous êtes victimes d'harcelement à cause d'une personne sur internet, soit le shitstorm est suffisament faible pour que vous vous en foutiez, soit n'hésitez pas à vous rapprocher des autorités. Les plateformes vont juste bloquer le compte, supprimer le message mais rien d'autre. Alors qu'un aller au tribunal va en calmer plus d'un. Et les menaces de représaile s: c'est du vent !
Bref, pour moi cet outil utilisé à bon escient permet de ne pas perdre d'oeuvre sur internet, de mémo ou autre. Et ça c'est vraiment cool !
Sur ce, portez vous bien.

Gif trouvé sur Tenor.
Photo by camilo jimenez.
Merci à Victor pour la correction de cet article